Millions of trades and transactions are done every day by the financial sectors, which face the challenging factors in the fiercely competitive world. To overcome the manual efforts and handle with ease and care, there are a plenty of sophisticated IT tools implemented today. As the amount of data growing rapidly, it is fed using the algorithms to handle and retrieve the data with safe and secure. But, the effectiveness is fully dependent on the performance and speed. The clutches of the effectiveness are handled by the applications, which is easier for the individual sector to manage the data. So, in order to handle the millions of data, an effective and smart application must be developed to meet the fast and furious world. To develop an effective application, a smart and cutting edge technology should be implemented to achieve all the goals. There is a luminous cutting edge technology introduced in the tech-market to resolve the hectic situations of the customers using the Fintech Services.
Let’s delve deep into this blog to identify a few barriers of the trending applications versus the assistance of smart applications.
Big Data Bottlenecks
There are a different types of data, including web log data, trade data, consumer data, research, market data, publications, public sentiment, social media, and more. Inconsistent data deficiencies can cause a critical problem in data aggregation on any sector and moreover, the FinTech industries are the ones being affected a lot. Some data warehouses are pre aggregated for a fixed view and those data might need to be aggregated again to provide a full risk analysis. In addition, the gap between the different network hops might also lead to the slow processing of data. So, to overcome these challenges to reduce the calculations, retrieval of data and times, a unified data layer should be implemented. Having a unified data layer supporting the push and pull capabilities of the archived data in the data warehouse (Hadoop or Cloud Storage) is the only way to deliver continuous and on-demand results.
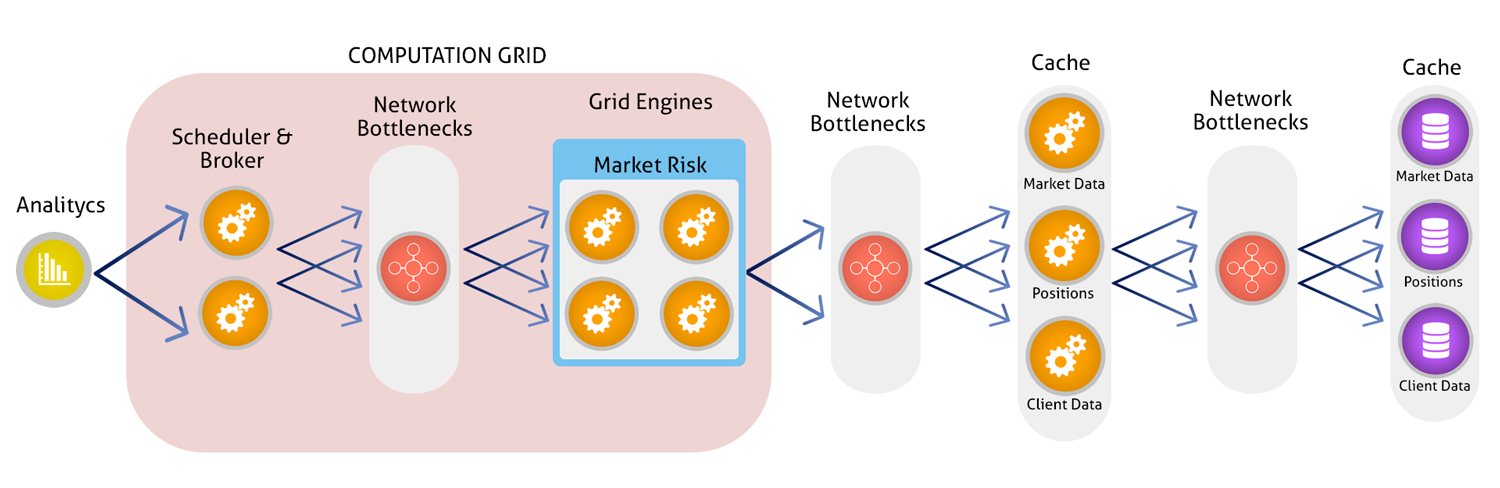
Real-Time Insight Solutions
Usually, the data is stored in the speed layer and the batch layer, where the archived data is stored such as HDFS (Hadoop Distributed File System) or S3. Data could be streamlined into both the layers, where the speed layer could hold the sliding window of the recent data. For instance, can retrieve the data of the last few days or last 24 hours. Users can query the appropriate layer as needed for their business and could query both the layers and merge the query results as per their need.
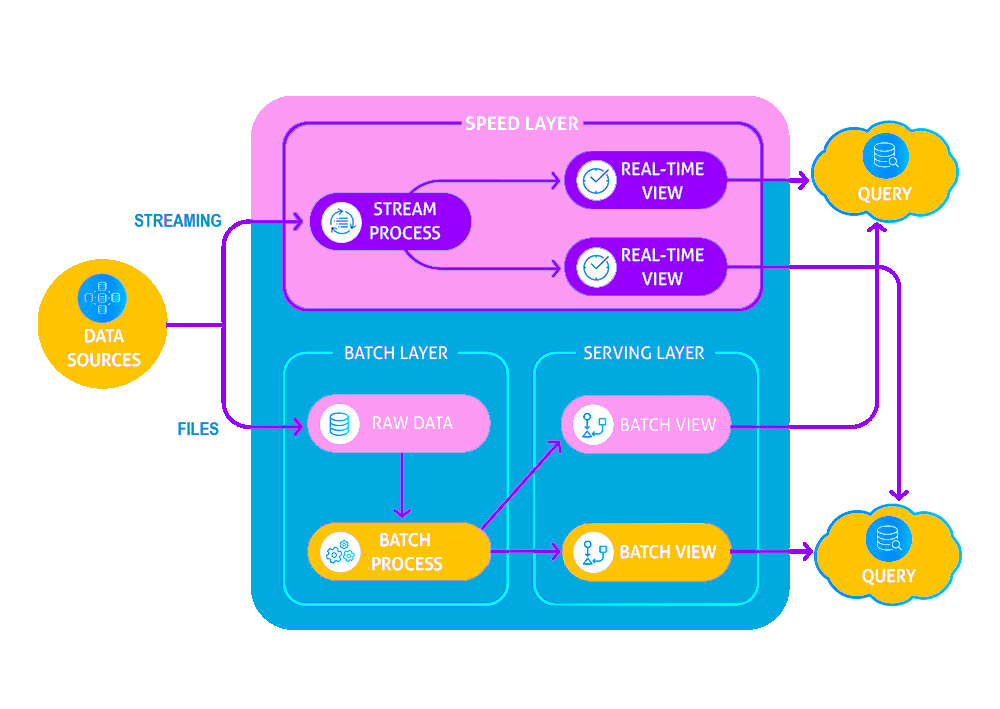
The above data shows that the system could be significantly simplified and improved by consuming the data directly, or from the selected message broker to a centralized data layer and by using a standardized API managing automatically (both the upstream and downstream) data tiers from a single platform.
On Concluding,
This process can be greatly simplified and accelerated by ingesting data directly, or from the selected message broker to a unified data layer and automatically managing data tiers (both upstream and downstream) from a single platform using a unified API.